Archive for category machine learning
Concentration of Measure I
Posted by Muhammad Alkarouri in machine learning, mathematics on May 27, 2009
The concept of Concentration of Measure (CoM) quantifies the tendency of an 

This is (hopefully) the start of a series of posts that will explain this concept. I would like to review a few concepts and definitions first though.
We denote by 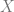
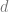
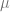



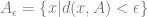
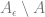
Now we can define the concentration rate of a space. The basic idea is: of all the sets 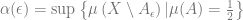
A few points can be made here. First, one would expect the set whose extension spans the smallest volume to be the one which has the smallest surface area, by virture of the relation between them. And in fact, one would be right, and this is the subject of the Isoperimetric Inequalities. Second, the concentration rate is the maximum volume outside an extended half-volume space possible, so using this property amounts to utilizing certain inequalities to limit, say, the volume of error. This is useful, for example, in the analysis of randomized algorithms. Third, the current definition yields one sided inequalities, but it is very easy to see that two sided algorithms can be derived which limit the volume outside a shell of width 
The more the measure is concentrated around a half-space, the smaller the concentration rate is. What we really want, and what CoM is about, is a very quick decay of the concentration rate as
And yes, it would be good if Posterous supported Latex..
Normal Law of Errors
Posted by Muhammad Alkarouri in machine learning, mathematics on April 26, 2007
Everybody firmly believes in it because the mathematicians imagine it is a fact of observation, and observers that it is a theory of mathematics.
Henri Poincaré
So, which is it? To apportion the blame, I suggest that the fact of observation be that “errors” are independent and identically distributed with finite variances. Observers may as well vote for Lyapunov’s set of conditions. I am sure that mathematicians are more than happy to shoulder the responsibility for the resulting Central Limit Theorem.
